机器人强化迁移学习指南:架设模拟和现实的桥梁
近年来,强化学习(Reinforcement learning)在人工智能领域中表现出了显著的性能,例如基于原始像素的 Atari 游戏,连续复杂控制策略的学习,以及在围棋游戏 Go 中超越人类的表现等。
,这些成功大多是在仿真、视频游戏等非物理环境中实现的,强化学习在物理系统上的复杂策略仍存在很大的挑战。强化学习需要与现实环境进行大量的交互,机器人强化学习从现实环境中获取样本的代价极高,,针对复杂运动技能的机器人强化学习是一个具有挑战性且尚未解决的问题,而迁移学习是实现物理机器人强化学习的重要策略。
本文聚焦如何利用迁移学习,使强化学习能够在模拟环境中进行训练,而在实际的物理机器人领域中得到应用。
机器人的强化迁移学习背景介绍
机器之心在之前的文章中对一般的强化迁移学习进行过梳理,我们来回顾一下
强化学习是一种根据环境反馈进行学习的技术。强化学习 agent 辨别自身所处的状态 (state),按照某种策略决定动作(action),并根据环境提供的奖赏来调整策略,直至达到最优。
马尔可夫决策 MDP(Markov Decision Process)是强化学习任务的标准描述,我们定义一个任务 M,用四元组< S , A , T, R>表示,其中 S 是状态空间,A 是动作空间,T 是状态转移概率,R 是奖赏函数。state-action 空间 S×A 定义了任务的域,状态转移概率 T 和奖赏函数 R 定义了任务的目标。
当强化学习的状态动作空间 S×A 很大时,为了寻找最优策略,搜索过程非常耗时。,学习近似最优解所需的样本数量在实际问题中往往令人望而却步。无论是基于值的方法还是基于策略的方法,只要问题稍稍变动,之前的学习结果就会失效,而重新训练的代价巨大。,研究者们针对强化学习中的迁移学习展开了研究,希望能够将知识从源任务迁移到目标任务以改善性能。
上文中提到的样本数量、学习结果针对不同任务失效等这些在一般强化学习中存在的问题在机器人强化学习中尤其突出。现有的机器人强化学习方法大多只能完成单个任务,而无法在不同的任务之间推广,或者仅通过收集很少数量的现实机器人经验来概括一些任务策略,其性能无法满足实战的要求。将迁移学习引入机器人强化学习,目的是利用模拟环境中的数据辅助现实机器人学习。机器人强化学习中的迁移学习称为「模拟到现实(Sim-to-real)方法」,具体是指在模拟环境中收集数据并训练机器人控制策略,然后进行迁移学习,将训练获得的控制策略(新技能)应用于物理现实中的机器人。
,机器人的强化迁移学习也并不容易,因为并不存在能够完美捕捉现实的模拟器(环境),模拟与现实之间存在「现实差距」(Reality Gap),模型的输入分布在策略训练(模拟)和策略执行(现实)之间存在动态变化和差异性。如果继续在这种有缺陷的模拟环境中训练策略产生控制行为,这种行为无法应对现实环境中的任何微小变化。,对于一些机器人动作模拟问题(如滑动摩擦力和接触力),其背后的物理现象仍然没有在模拟器上百分百模拟,这就意味着根本不可能在模拟环境中对一些现实中的机器人动作进行完全精确的模拟。
目前,改进机器人的强化迁移学习主要有几类方法
1、试图在模拟和现实之间建立明确的一致性,缩小模拟和现实的差距;
2、对模拟阶段的策略训练进行随机化处理,使其能够推广到相关的动力学现实策略中;
3、在模拟阶段得到一个足够好的策略,能够在现实的机器人策略执行过程中快速适应现实世界;
4、提高对机器人动作物理现象本身的模拟水平;
5、可以通过引入其他学习手段提升机器人强化迁移学习的效果。
本文对机器人强化迁移学习的最新进展进行了梳理,对不同的方法进行了简要分析。
机器人的强化迁移学习最新进展
1、缩小模拟和现实的差距
Florian Golemo, Adrien Ali Taiga, et al, 「Sim-to-Real Transfer ith Neural-Augmented Robot Simulation,」PMLR 2018,
在大部分机器人模拟器中,只能通过有限的参数对物理环境进行模拟,与现实情况对比总有误差。这篇文章提出,使用从现实机器人中收集的数据训练一个递归神经网络来预测模拟和现实世界之间的差距,经过训练缩小该误差,从而提升机器人强化迁移学习的效果,称为神经增强模拟(Neural-Augmented Simulation,NAS)。NAS 可以与不同强化学习算法相结合,在保证快速离线训练的,较好的学习迁移策略。为了有效捕获状态(state)中不满足标准马尔可夫假设的偏差,本文引入递归神经网络进行学习,以 LSTM 为例具体介绍。
针对强化学习中的马尔可夫决策 MDP,假设源域(模拟环境)和目标域(现实环境)具有相同的动作(action),两个域中的任务分别为 Ds=< S_s , A , p_s, r_s>和 Dt=< S_t , A , p_t, r_t>,假设奖赏相同(即 r_s=r_t),假设有权访问源域并可将其重置为特定的状态。作者利用 LSTM 建立一个源域和目标域之间的差距模型,学习从源域中的轨迹到目标域中轨迹的映射,通过使源域中的模拟对象逼近目标域中现实机器人的轨迹来提高模拟的质量,从而缩小模拟和现实的差距。给定行为策略μ(可以是随机的或由专家提供),从目标域中收集现实机器人的轨迹。
从目标域分布中采样初始状态 s_0~p_t(s_0),源域也从相同的初始状态开始训练。在每个学习过程中,根据行为策略 a_i∼μ(s_t) 对操作进行采样,在两个域中分别处理并进行迁移学习,将源域重置为目标域状态,重复该过程,直到结束。最终得到的行为轨迹为
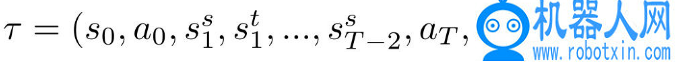
在从现实机器人中收集数据之后,使用训练模型φ(LSTM)来预测目标域中 s_{i+1} 的值。通常来说,两个域状态之间的差距很小,计算网络输出校正项为
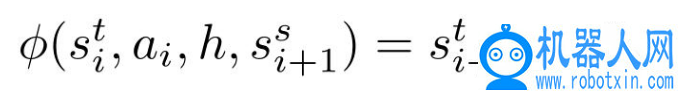
机器人强化迁移学习指南架设模拟和现实的桥梁
其中 h 是网络的隐藏状态。
训练得到模型φ后,将其与模拟环境相结合,以学习稍后将迁移到现实目标环境的策略。本文选择 PPO[1] 作为强化学习的方法,在每个学习过程中,将源域中的当前状态迁移至模型φ,计算目标环境中对当前状态的估计,根据该估计值选择动作
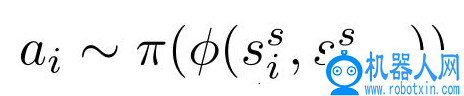
然后将源域状态设置为目标域状态的当前估计值,从而允许模型修正来自源域的轨迹,使它们更接近目标域中的相应轨迹,以缩小两个域之间的差距。
本文与如下几种方法进行实验对比
1、forard 模型策略使用 LSTM 和从目标域收集的数据训练前向动态模型,然后仅使用此模型训练策略(没有来自源域的轨迹调整);
2、专家策略: 直接在目标域内训练;
3、源策略直接将在源域中训练得到的策略应用于目标域,而不进行任何自适应处理;
4、传输策略使用 NAS 训练的策略。
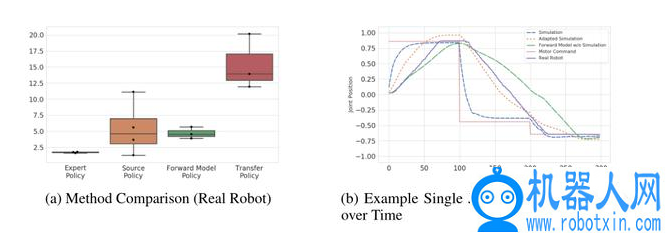
图 1. 不同方法的效果对比
图 1 给出不同方法的实验效果。图 1(a)比较每种方法给出 3 个策略的 20 次奖赏平均值。图 1(b)在模拟(绿色虚线)、现实机器人(蓝色实线)上接收目标位置(紫色虚线)时的单关节行为比较,以及根据 forard 模型(红色虚线)和本文提出方法(黄色虚线)进行估计的结果。
本文使用 Popy Ergo Jr 机器人手臂进行实验,将两个机器人固定在一块木板上,两个机器人面朝对方,两个机头在静止位置相隔 5 毫米。一个机器人拿着一把「剑」(铅笔),另一个拿着一个盾牌。护盾机器人(「防御者」)每 2.5 秒移动一次,移动到一个任意位置,在该位置护盾在对手可触及的范围内。剑形机器人(「攻击者」)是唯一可直接控制的机器人。每一个工作段(episode)持续 10 秒,攻击者的目标是尽可能频繁地触摸盾牌。
图 1(a) 中结果显示专家策略(直接在现实机器人中训练的策略)的效果最差,其主要原因是,在这篇文章所述的实验条件下
(a)在现实环境中的命中检测并不完美(该现象与在模拟中类似),并且由于不是每一次命中都能够成功检测到,得到的奖赏非常稀疏。
(b)由于攻击者机器人经常将剑卡在对手身上、自己身上或环境中,在某些任务中从现实环境找到并提取机器人状态和动作并不像模拟中那么容易。,源策略和 forard 模型策略的效果差不多,而使用 NAS 训练的传输策略效果最优。
图 1(b) 给出了对于一个给定任务不同方法估计关节位置的准确度差异。尽管 forard 模型能够很好的估计从目标域中收集的数据,但由于没有根据源域的轨迹进行任何调整,仅使用 forard 模型训练得到的策略效果较差。出现这样的问题是由于 forard 模型过度拟合训练数据,而不能够很好的推广到其他情况。而能够有效避免这一问题也是本文提出方法的一个关键优势NAS 通过引入神经网络来增强学习,能够有效利用来源于不同任务的学习增强信息,从而提升策略水平。
2、随机化处理策略训练
X. Peng, M. Andrychoicz, W. Zaremba, and P . Abbeel,「Sim-to-real transfer of robotic control ith dynamics randomization,」CoRR, 2017.
机器人的强化迁移学习基于模拟环境中丰富的样本数据来训练 agent。经典算法一般基于固定的动态模型训练,例如上一篇文章中介绍的是基于确定的状态和动作完成训练的。这种情况下经常会导致 Reality Gap 的问题。这篇文章提出来的思路是通过随机化处理状态和动作,训练得到动态的、高适应性的策略,从而实现在现实物理系统中应用策略,不需要再进行任何训练或调整就能有效应对现实世界中的动态变化。
,引入一组动态参数μ,用于表征模拟场景的动态变化概率 p(s_{t+1} | s_t, a_t, µ)。策略训练的目标是最大化动态参数分布的期望值 E
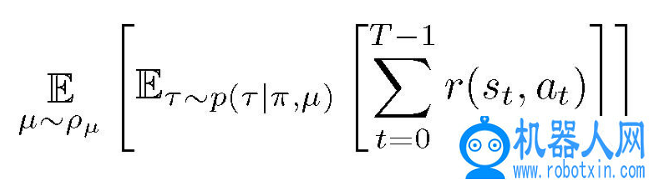
基于动态参数训练得到的策略能够更好的满足现实环境中的动态情况推广要求。具体的,文章选择以一个 7 自由度的取物机器人手臂在一个推球任务中的训练为例介绍随机化策略。明确每个阶段(episode)的目标「g」为将冰球移动到桌面的随机目标位置。机器人及模拟场景见图 2。

图 2. 推球任务机器人及模拟 MuJoCo 模型
,确定状态和动作。使用手臂的关节位置和速度、抓取器的位置以及冰球的位置、方向、线速度和角速度等来表示状态,生成一个 52 维的状态空间;观测噪声对传感器中的不确定性进行建模,并作为独立的高斯噪声应用于每个状态特征。动作由指定位置控制器的目标关节角度来表示,目标角度指定为相对于当前关节旋转的相对偏移,生成一个 7 维动作空间。
第二,对模拟 MuJoCo 模型中的状态和动作进行随机化处理,从而产生更多训练样本。在本文的示例场景中具体包括机器人身体各环节的质量、各关节阻尼、冰球的质量摩擦和阻尼、桌子的高度、位置控制器增益、动作间隔时间,以及观测噪声。总共包含了 95 个随机参数。
第三,制定适应性策略。虽然动态参数μ在模拟环境中很容易获得,但对于部署在现实环境中的策略未必适用。为了弥补它们之间的误差,引入一个在线系统识别模块φ(s_t,h_t)=μ,该模块利用状态和动作的历史情况 h_t=[a_t-1,s_t-1,a_t-2,s_t-2,…] 来预测动态参数μ。然后,将预测的参数用作通用策略的输入,该策略根据当前状态和推断的动态参数π(a_t | s_t,μ) 对操作进行采样。关于历史状态μ的计算方式不是本文讨论的重点,详细内容可参照 [2]。
使用递归模型π(a_t | s_t, z_t, g) 将动态参数嵌入到策略中,其中 z_t=z(h_t) 表征过去的状态和动作,从而提供策略用于推断系统动态变化的机制。
第四,完成策略训练。在策略训练过程中,通过奖赏函数的设计保证 agent 完成任务目标。这篇文章使用 Hindsight Experience Relay(HER)基于稀疏奖赏函数训练策略 [3],具体为考虑轨迹τ,目标 g 在轨迹调整的过程中始终不满足,每一步的奖赏值为-1。一旦确定新目标 g』,就可以计算原始轨迹的奖赏在新目标下的轨迹。与 g』相关的奖赏不再是-1。使用 HER 替代过去的经历,可以使用比原始记录轨迹更好的样本来训练 agent。
,这篇文章还引入一个适合于连续控制的循环确定性策略梯度(Recurrent Deterministic Policy Gradient,RDPG)实现强化学习。具体做法是将递归价值函数建模为 Q(s_t, a_t, y_t, g, µ),其中 y_t= y(h_t)。价值函数仅在训练期间使用,并且已知模拟器的动态参数μ,使用μ作为价值函数的附加输入,而不是策略的附加输入。
图 3 给出了策略(π)和价值(Q)网络的结构图示,其中输入为当前状态 s_t 和前一个动作 a_t-1。策略(π)网络架构如下每个网络由一个前馈分支和一个递归分支组成,后者的任务是从过去观测值推断动态参数。内部存储器使用一层 LSTM 单元建模,并且仅提供推断动态参数所需的信息(例如,s_t 和 a_t-1)。由于目标 g 在每个阶段都是确定的,不包含任何有关的动态信息(时序信息),仅由前馈分支处理。,由于当前状态对于确定当前时间步长特别重要,还向前馈分支提供一个副本作为输入。然后,将两个分支计算的特征连接起来,由两个附加的全连接层(每个层 128 个单元)进行处理。价值(Q)网络整体架构类似。
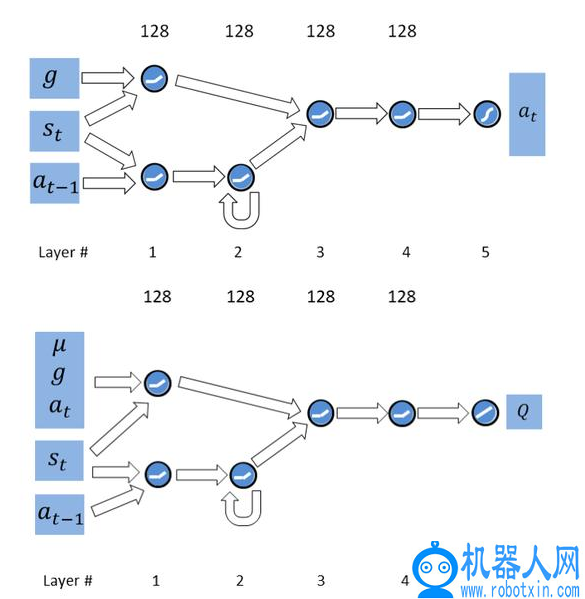
图 3. 策略和价值网络的结构图示
在这篇文章以及我们上面介绍的神经增强模拟(NAS)方法中都提到了递归神经网络(LSTM)的使用。其中,NAS 使用 LSTM 建立源域和目标域之间的差距模型,在每个学习过程中,将源域中的当前状态迁移至 LSTM 模型,计算目标环境中对当前状态的估计,根据该估计值选择动作然后将源域状态设置为目标域状态的当前估计值,从而允许模型修正来自源域的轨迹,使它们更接近目标域中的相应轨迹,以缩小两个域之间的差距。而在本文中,引入 LSTM 是作为强化学习策略训练网络结构的内部存储器使用。
文章给出了实验对比,评估了不同模型在模拟和真实 Fetch arm 上部署的性能,分别为使用图 3 中结构的 LSTM、一种只接受当前状态作为输入的无记忆的前馈网络(FF)、无记忆无随机化前馈网络(FF-no-Rand)、增加了 8 个先前观察到的状态和动作的历史输入的前馈网络(FF+Hist)。图 4 为不同模型在模拟和现实机器人上完成推送任务的性能,只使用模拟数据训练策略。LSTM 与 FF+Hist 在模拟环境中效果相当,但 LSTM 能够更好地适应动态变化的物理系统(现实机器人),而未经随机训练的前馈网络(FF-no-Rand)则根本无法在现实机器人的动态环境中执行任务。
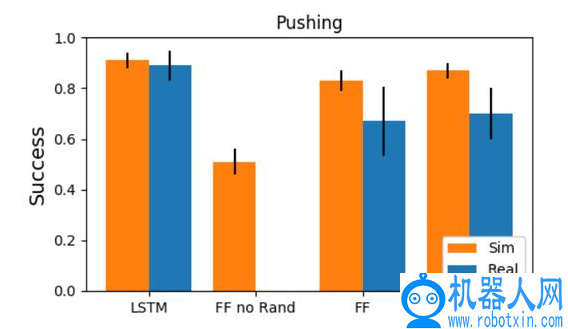
图 4. 不同模型在模拟和现实机器人上进行推送任务时的性能对比
3、直接提高策略质量
Zhanpeng He, Ryan Julian, et al,「Zero-Shot Skill Composition and Simulation-to-Real Transfer by Learning Task Representations,」
这篇文章提出的方法试图在模拟环境中学习一个能够快速适应现实世界的健壮的策略。文章的基本思想是利用强化学习和变分推理学习技能的嵌入空间,之后将这些技能在真实机器人上转移和组合实现。通过引入模型预测控制(Model-Predictive Control,MPC)学习任务表示,实现了在现实机器人中不经微调处理即可成功的完成未知任务,从而使得迁移过程更加健壮,能够显著减少训练策略所需的仿真样本数,从而得到相关任务的策略。MPC 是直接利用学习到的潜在空间和模拟来寻找新任务的在线策略。
该方法包括四个关键部分变分推理、策略梯度强化学习、模型预测控制(MPC)和物理模拟。其中,使用变分推理 (variational inference) 来学习一个低维的技能潜在空间,使用强化学习学习以这些潜在技能为条件的控制策略。而由于对于给定的潜在技能,策略的精确长时间行为很难预测,在实际机器人上执行之前,使用 MPC 和在线仿真来评估模拟中的潜在技能计划。
变分推理
在多任务设置中,使用 T={1,...,N} 预先定义一组低级技能,以及每项技能的奖赏函数 r(s,a)。除了像经典强化学习方法中学习低级技能策略π_θ,作者提出使用类似变分推理的办法再学习一个嵌入函数 p_φ。使用一个潜在变量 z 参数化低级技能库,而真正的技能标识 t 包含在嵌入函数 p_φ的策略中。也就是说,并不以显示 ID 的方式直接向策略给出技能 ID,而是通过随机嵌入函数 p_φ将编码为独热向量(one-hot vector)的技能 ID t 输入到策略中,生成一个潜在向量(latent variable)z。将这个相同的 z 值输入到整个策略中,以便轨迹中的所有步骤都与相同的 z 值相关联。
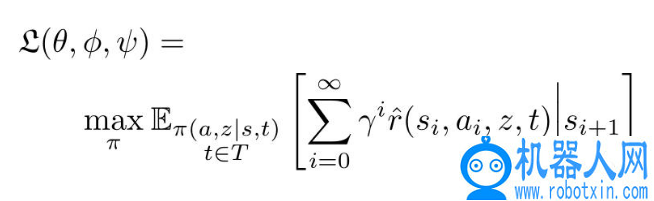
其中有参数
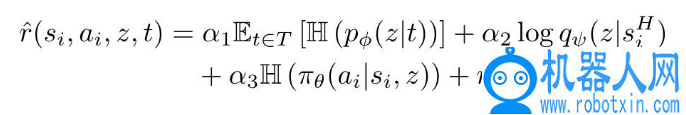
为了辅助嵌入函数的学习,这篇文章还增加学习了一个推理函数 q_Ψ,其作用为给定一个状态唯一的轨迹窗口,预测生成潜在向量 z。它在给定一个仅包含状态的轨迹窗口的情况下,预测生成该轨迹时输入到低级技能策略的潜在向量 z。定义一个增强的奖赏函数,它鼓励策略为不同的潜在向量探索不同的轨迹,学习的过程并行学习策略、嵌入函数 p_φ和推理函数 q_Ψ。,文章还添加了一个策略熵奖励 H(πθ(ai|si, z)),它确保策略不会崩溃为每种技能的单个解决方案。
策略梯度强化学习
本文使用近端策略优化(PPO)来训练强化学习的策略和嵌入网络,使用 MuJoCo 物理引擎来实现 Sayer 机器人仿真环境,使用多元高斯分布来表示策略、嵌入和推理函数,由多层感知器的输出参数化实现其平均和对角协方差,,利用强化学习算法对策略分布和嵌入分布进行联合优化,利用监督学习和简单的交叉熵损失对推理分布进行训练。
模型预测控制(MPC)和物理模拟
在前两步强化学习中,机器人是在一个仿真框架中进行训练的,在适应未知任务时,可以将训练前的仿真作为一种辅助工具。这使得机器人可以选择一个潜在的在线技能,只需要满足任务的局部最优约束,而不要求在训练期间就存在该任务,这也被成为是一种 zero-shot 任务执行。
这种处理方法与我们上面介绍的「缩小模拟和现实的差距」以及「对模拟阶段的策略训练进行随机化处理」不同,上述两种方法尽管对模拟环境进行了大量的仿真处理工作,但都没有证明能够提供现实世界中通用机器人所需的适应能力。本文的方法是机器人强化迁移学习中一种适应实际探索的更高层次的补充方法。
,将在策略梯度强化学习阶段得到的潜在技能向量序列输入到模型中,每个潜在的技能都与不同的预学习行为相关。通过选择这些预学习行为序列(通过技能嵌入持续参数化),能够有效解决新任务的适应问题。重复使用模拟阶段的预训练结果,作为在现实场景中适应未知任务时的预见工具,包括技能嵌入向量概率分布 p_φ、潜在条件低级技能策略 π_θ等。MPC 过程如图 5 所示
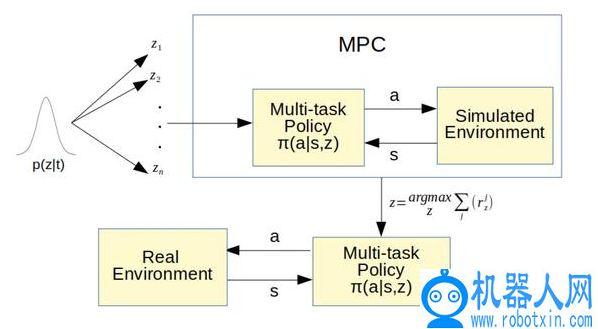
图 5. 嵌入函数和多任务策略的模型预测控制
候选潜在向量 Z={z_1,...,z_k} 是根据概率分布 p_φ得到的。在 T 个时间步长的时间范围内,对策略 π_θ进行抽样,以潜在的候选策略为条件,执行模拟环境的操作,得到每个潜在向量 z_i 的奖赏 Ri_ne。计算得到最大奖赏值
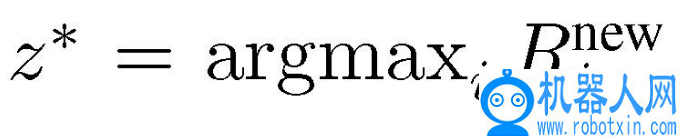
再以此为依据调整多任务策略。重复这个 MPC 过程来依次选择和执行新的潜在向量,直到任务完成。
本文通过在 Sayer 机器人上完成两个排序任务来评估不同的方法绘制一个点序列并沿着一个序列路径推一个盒子。对于每一个实验,机器人必须通过在嵌入学习过程中学习到的排序技能来完成一个整体任务。
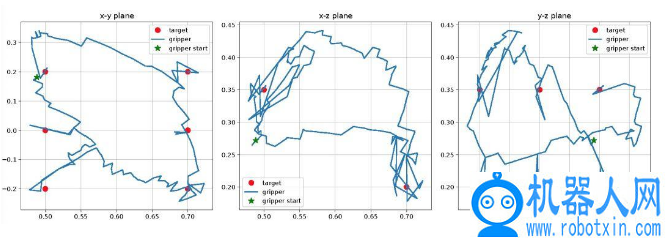
图 6. 在现实机器人上进行矩形绘制实验的夹具位置图,在这个实验中,未知任务是画一个矩形
图 7. 在现实机器人上进行三角形绘制实验的夹具位置图,在这个实验中,未知任务是移动夹持器来画一个三角形
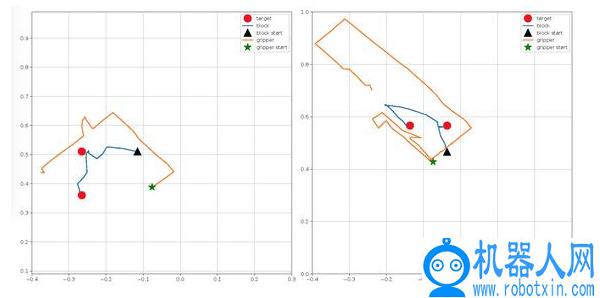
图 8. 现实机器人实验中的挡块位置和夹持器位置图,(左图)机器人将盒子向左推,然后向下推;(右图)机器人将盒子向上推,然后向左推
图 6-8 给出了使用本文提出的方法完成 Sayer 机器人画和推两个动作的实验。其中,Sayer 机器人通过实时选择 62 个潜在向量,在 2 分钟内成功地完成了未知的矩形绘制任务,选择 53 个潜在向量,在 2 分钟内完成了未知的三角形绘制任务。Sayer 机器人选择 3 个潜在变量,在大约 1 分钟的时间内完成了未知的左下推任务,选择 8 个潜在变量,在大约 1.5 分钟的时间内完成了未知的上左推任务。
4、力的转移学习和控制
Rae Jeong , Jackie Kay ,et al,「Modelling Generalized Forces ith Reinforcement Learning for Sim-to-Real Transfer」,
这篇文章主要研究如何有效地利用少量的现实世界数据来改善仿真效果,从而实现机器人的强化迁移学习。通过学习一个依赖于状态的广义力模型实现强化迁移学习,使用神经网络作为表达函数逼近器来模拟动力系统的约束力。
在前三篇文章中,不管是一致性处理、随机化处理还是 zero-shot 的策略学习,都不使用任何现实世界的数据来改进模拟器,并且需要手动调整物理参数的选择和范围以改进模拟的效果。这篇文章的思路是,直接引入现实世界中机器人的物理动作(作用力),而不是仅依靠模拟环境中的参数,从而改进模拟器的效果。
,介绍一下力学相关的背景知识。在经典力学中,任何受外力作用的刚体系统都可以用下列运动方程来描述
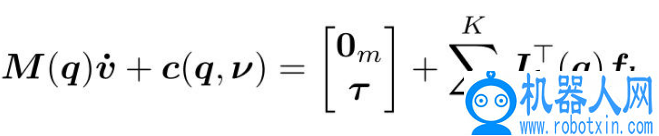
其中 q 和 v 分别是系统配置和速度,m 为质量矩阵;c 为偏心力,包括科里奥利力、离心力、关节摩擦力和重力。τ表示内部、驱动、扭矩,0_m 表示未驱动变量。6 维的力 f_k 通过对应的接触雅可比 J_k 映射为广义力。如果系统相互作用或与环境相互作用,则上式还需要补充描述接触约束的附加方程。在不假设接触类型的情况下,本文将这些约束表示为相关系统状态的一般函数
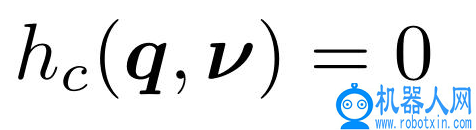
仍使用 MDP 描述强化学习过程。强化学习的目标是找到最佳策略π
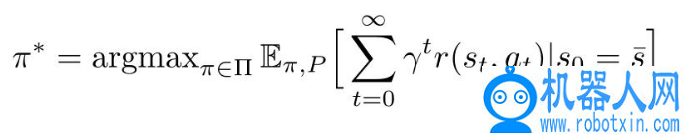
引入一个动作值函数,利用一步 Bellman 方程 Q(s, a) 计算策略π的期望奖赏之和
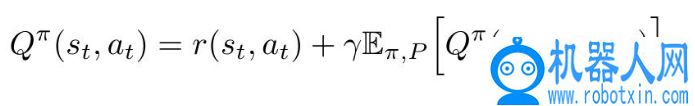
在策略评估阶段通过策略外强化学习计算得到期望奖赏之和,在策略改进阶段利用策略评估结果改进策略本身。公式(1)和(2)代表的策略优化和期望奖赏值计算两个步骤迭代执行。
针对机器人强化迁移学习问题,除了驱动力和外力外,在运动方程中添加了一个与状态相关的广义力项
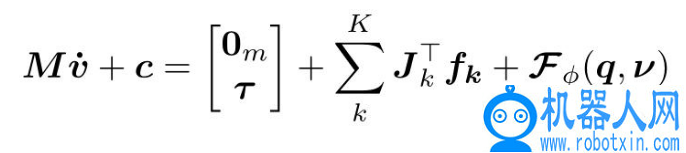
由此,得到一个以矢量θ为参数的混合离散动力学模型 s_t+1=f_θ(s_t , a_t),以当前状态和作用为输入、下一状态 s_{t+1} 的预测为输出。目标是找到参数向量θ,它使沿水平面 t 的动力学间隙最小化
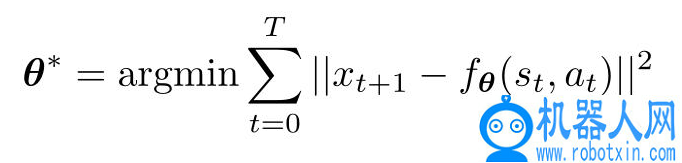
此时,强化学习的目标函数为
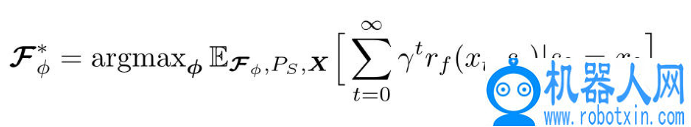
其中,P_S 为未修正力学动态模型的转移概率分布。将得到的广义力模型(Generalized Force Model,GFM)F_φ用作过渡模型 P_f,然后,使用带有转移概率分布 P_f 的混合模型为感兴趣的控制任务训练策略,得到以下强化学习目标

图 9. 所提出方法步骤的描述
图 9 给出所提出方法步骤的完整描述。1)使用原始模型参数对 agent 进行模拟训练。2)使用步骤 1 中训练得到的 agent 收集现实世界的数据。3)学习广义力模型(GFM)将仿真初始化为现实世界轨迹的初始状态,选择与现实机器人相同的动作推进模拟过程。
本文将所提出的方法与三种基线方法进行了比较,分别是i)用原始动态模型训练的策略,ii)用原始模型训练的策略和使用课程学习的策略,以及 iii)用广义力随机扰动训练的策略和使用课程学习的策略。表 1 和表 2 分别为位置和姿态匹配的结果。本文的方法获得了与基线方法相比显著的改进,这也证明了引入现实场景中的力学参数对于改进强化迁移学习的效果有正向的作用。
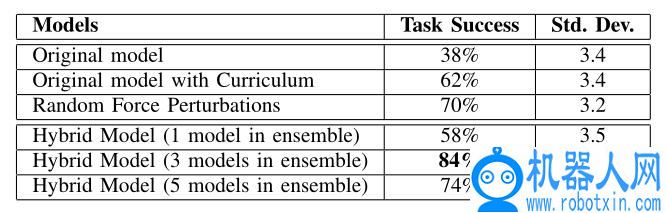
表 1. 位置匹配任务评估

表 2. 姿势匹配任务评估
这篇文章引入了状态相关广义力(Generalized Forces)建模和学习,以捕获模拟环境与现实环境间的差异。从力学角度分析,在控制相互作用力时,通常选择扭矩控制作为底层控制器,这篇文章认为在强化学习中使用扭矩控制并不常见,采用了「在运动方程中添加了一个与状态相关的广义力项(GFM)」的处理方式。未来的工作可以进一步探讨,使用本文提出的广义力模型是否有助于学习交互任务,也可以引入扭矩控制来控制机器人。
5、其它任务学习方法
Oier Mees , Markus Merklinger , et. al.,「Adversarial Skill Netorks- Unsupervised Robot Skill Learning from Video,」
这篇文章提出了一种对抗技能网络(Adversarial Skill Netorks,ASN),它仅依赖于未标记的多视图观察(视频输入)来学习任务不可知的技能嵌入空间,而不需要任何额外的监督信息,就能找到一个适用于不同任务域的嵌入空间。ASN 是作为 Sim-to-Real 方法的前置步骤提出的,它不仅适用于机器人的强化迁移学习,也适用于其它发现并学习可转移的技能任务。在这篇文章中,只进行了模拟环境中的实验验证,这与前四篇文章的分析是不同的。下一步,可以进一步研究扩展将 ASN 学习到的度量应用于现实世界中的强化学习任务中。
ASN 的主要目的是生成可以重复使用并适用于新任务的技能表现(Skill Representation),对应的嵌入空间具有如下特点
通用性多个任务可以在同一个嵌入空间中表示;
技能识别能力可以通过嵌入输入视频中的两个连续帧来描述技能,帧之间有时间延迟(步幅);
独立于任务的技能所提取的嵌入空间能够保证在不同环境中执行相同任务都具有良好的性能。
ASN 整体结构如图 10 所示。在对抗性框架中学习技能度量空间,其中编码部分使用最大化熵来保证通用性,鉴别器部分则使用最小化预测熵来提高对技能的识别能力。,最大化所有技能的边际类熵从而有效提取独立于任务的技能特征。
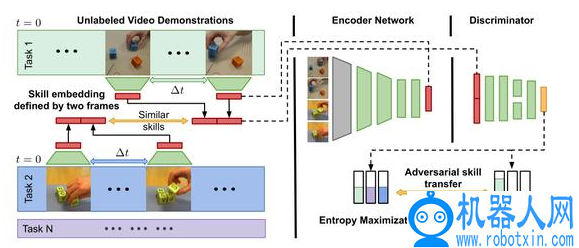
图 10. 对抗技能网络结构
,引入一种新的熵正则化方法,对抗性地联合训练两个网络编码器 E 和鉴别器 D。给定输入视频中的时间间隔为∆t 的两个连续帧(v,),定义一个未标记的技能嵌入向量 x=(E(v) , E()) 和 X={x^1,…,x^N}。编码器 E 将 d1×d2 的单个帧嵌入到 n 维的低维表示中,计算嵌入空间中的欧氏距离来比较帧的相似性。鉴别器 D 采用两个串联的嵌入式帧,定义一个未标记的技能 x 作为输入,输出为 y_c。
使用度量学习损失和最大化鉴别输出的熵来更新编码器参数。给定两个视图对(v1,v2),给定边际参数λ,从不同角度同步视频
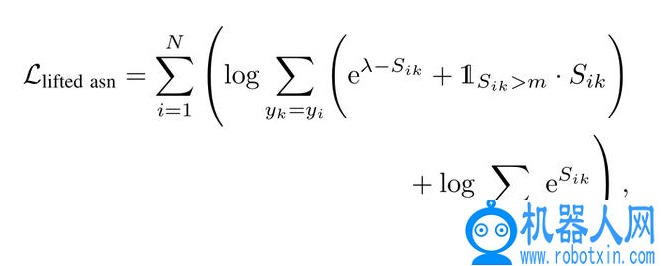
其中,S_ij= E(X_i) · E(X_j)。在给定一个未标记的技能嵌入 x 的情况下,鉴别器网络 D 将熵最小化,以确定该技能来自哪个任务 C,值得注意的是,D 仅在训练阶段使用。这篇文章对鉴别器的处理是根据预测类别分布的信息论测度,在技能嵌入空间中将未标记的技能划分为多个类别,而不需要对 p(x) 进行显式建模。编码器试图最大化熵 H[p(y_c | x,D)],在最佳情况下,能够保证任务类的均匀条件分布。具体地说,将嵌入技能样本 X 上的条件熵的经验估计定义为
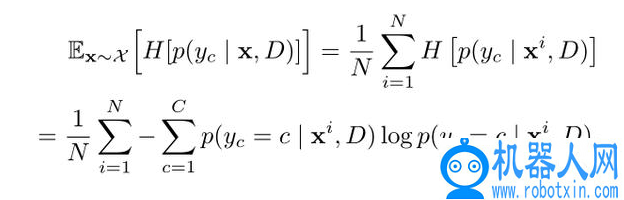
引入一个附加的正则化算子进一步增强所有任务类的等价使用,对应于最大化均匀的边缘分布
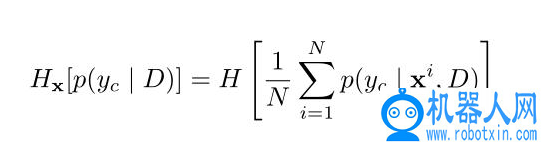
为了分离学习到的度量和任务 ID 的映射,添加一个采样的潜在变量 z。使用重参数化技巧通过随机节点反向传播利用潜在变量 z 的 Kullback-Leibler 散度正则化,使得 D 能够有效表征技能的相似性质。最终,E 和 D 的目标函数为

图 11 给出了 ASN 应用于机器人学习的实验结果,其中使用时间对比网络(Time-Contrastive Netorks,TCN)作为对比基线算法。将使用 ASN 学习到的度量集成到机器人强化学习的 agent 中,以模拟给定单个视频演示的不可见任务。具体说明,为了学习颜色叠加(C)任务的连续控制策略,训练了两块叠加(A)和颜色推送(B)任务的嵌入。在给定关于叠加和颜色叠加任务的嵌入训练结果的前提下,学习预先未知的颜色推送任务的连续控制策略。该实验中使用策略优化算法 PPO 训练 agent。实验结果证明了在该场景下 ASN 的有效性,ASN 能够将学习到的技能用于新任务,且获得了较好的性能。
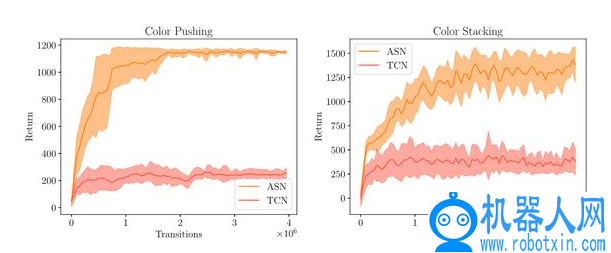
图 11. 使用学习的奖赏函数训练 PPO 对不可见的颜色推送和颜色叠加任务的连续控制策略的结果。图中显示了五次训练的平均值和标准差。
文章小结
在本文中,我们针对机器人的强化迁移学习问题分析和梳理了近年来的重要研究方向和进展。机器人的强化迁移学习的核心在于基于模拟环境中丰富的样本数据来训练机器人控制策略,通过引入迁移学习的方法,将控制策略转移于现实中的物理机器人。,研究和改进主要集中于提升策略迁移应用于机器人的效果。通过本文的分析我们可以看到,研究人员重点考虑的是改进策略本身、缩小模拟环境与物理环境之间差异等手段,一方面努力提升模拟环境中状态和动作的普适性,另一方面尝试将物理环境中的一些参数引入到模拟环境策略训练中。其中,第一篇文章使用从现实机器人中收集的数据训练 LSTM 来预测模拟和现实世界之间的差距,而第二篇文章是对状态和动作进行随机化处理,从而得到动态的、高适应性的策略,其中也使用了 LSTM,在这里 LSTM 的作用是计算推断动态参数所需的信息。第三篇文章是在模拟阶段利用变分方法直接求得足够好的策略,实现了在现实机器人中不经微调处理即可成功的完成未知任务,从而使得迁移过程更加健壮。第四篇文章直接引入现实世界中机器人的物理动作,而不再是仅依靠模拟环境中的参数,从而改进模拟器的效果。第五篇文章提出了一种对抗技能网络来找到适用于不同任务域的嵌入空间,该方法不仅适用于机器人的强化迁移学习,也适用于其它发现并学习可转移的技能任务。
机器人工业设计
- 11个工业智能机器人
- 工业机器人技术专业专升本难吗 工业机器人技术
- 工业机器人就业方向及前景专科专业
- 国内工业机器人龙头公司 国内工业机器人龙头企
- 工业机器人岗位职责有哪些
- 工业机器人技术专业需要学什么
- 工业机器人技术难学吗 工业机器人技术是学什么
- 世界上第一台工业机器人资料
- 工业机器人技术大专毕业工资 工业机器人技术专
- 工业机器人方向研究生好就业吗
- 工业机器人编程主要学什么 工业机器人编程主要
- 工业机器人技术容易学吗 工业机器人学起来难不
- 学工业机器人就业前景分析 学工业机器人就业前
- 工业机器人编程需要学什么方向 工业机器人编程
- 工业机器人编程属于什么专业 工业机器人编程专
- 工业机器人的专业 工业机器人的专业课程有哪些